
Clients often ask for strategies that trade on very short time frames. Some are possibly inspired by “I just made $2000 in 5 minutes” stories on trader forums. Others have heard of High Frequency Trading: the higher the frequency, the better must be the trading! The Zorro developers had been pestered for years until they finally implemented tick histories and millisecond time frames. Totally useless features? Or has short term algo trading indeed some quantifiable advantages? An experiment for looking into that matter produced a surprising result.
It is certainly tempting to earn profits within minutes. Additionally, short time frames produce more bars and trades – a great advantage for strategy development. The quality of test and training depends on the amount of data, and timely price data is always in short supply. Still, scalping – opening and closing trades in minutes or seconds – is largely considered nonsense and irrational by algo traders. Four main reasons are given:
- Short time frames cause high trading costs – slippage, spread, commission – in relation to the expected profit.
- Short time frames expose more ‘noise’, ‘randomness’ and ‘artifacts’ in the price curve, which reduces profit and increases risk.
- Any algorithms had to be individually adapted to the broker or price data provider due to price feed dependency in short time frames.
- Algorithmic strategies usually cease working below a certain time frame.
Higher costs, less profit, more risk, feed dependency, no working strategies – seemingly good arguments against scalping (HFT is a very different matter). But never trust common wisdom, especially not in trading. That’s why I had not yet added scalping to my list of irrational trade methods. I can confirm reasons number 3 and 4 from my own experiences: Below bar periods of about 10 minutes, backtests with price histories from different brokers began to produce noticeably different results. And I never managed to develop a strategy with a significantly positive walk-forward test on bar periods less than 30 minutes. But this does not mean that such a strategy does not exist. Maybe short time frames just need special trade methods?
So I’ve programmed an experiment for finding out once and for all if scalping is really as bad as it’s rumored to be. Then I can at least give some reasoned advice to the next client who desires a tick-triggered short-term trading strategy.
Trading costs examined
The first part of the experiment is easily done: a statistic of the impact of trading costs. Higher costs obviously require more profits for compensation. How many trades must you win for overcoming the trading costs at different time frames? Here’s a short script (in C, for Zorro) for answering this question:
function run()
{
BarPeriod = 1;
LookBack = 1440;
Commission = 0.60;
Spread = 0.5*PIP;
int duration = 1, i = 0;
if(!is(LOOKBACK))
while(duration <= 1440)
{
var Return = abs(priceClose(0)-priceClose(duration))*PIPCost/PIP;
var Cost = Commission*LotAmount/10000. + Spread*PIPCost/PIP;
var Rate = ifelse(Return > Cost, Cost/(2*Return) + 0.5, 1.);
plotBar("Min Rate",i++,duration,100*Rate,AVG+BARS,RED);
if(duration < 10) duration += 1;
else if(duration < 60) duration += 5;
else if(duration < 180) duration += 30;
else duration += 60;
}
Bar += 100; // hack!
}
This script calculates the minimum win rate to compensate the trade costs for different trade durations. We assumed here a spread of 0.5 pips and a round turn commission of 60 cents per 10,000 contracts – that’s average costs of a Forex trade. PIPCost/PIP in the above script is the conversion factor from a price difference to a win or loss on the account. We’re also assuming no win/loss bias: Trades shall win or lose on average the same amount. This allows us to split the Return of any trade in a win and a loss, determined by WinRate. The win is WinRate * Return and the loss is (1-WinRate) * Return. For breaking even, the win minus the loss must cover the cost. The required win rate for this is
WinRate = Cost/(2*Return) + 0.5
The win rate is averaged over all bars and plotted in a histogram of trade durations from 1 minute up to 1 day. The duration is varied in steps of 1, 5, 30, and 60 minutes. We’re entering a trade for any duration every 101 minutes (Bar += 100 in the script is a hack for running the simulation in steps of 101 minutes, while still maintaining the 1-minute bar period).
The script needs a few seconds to run, then produces this histogram (for EUR/USD and 2015):
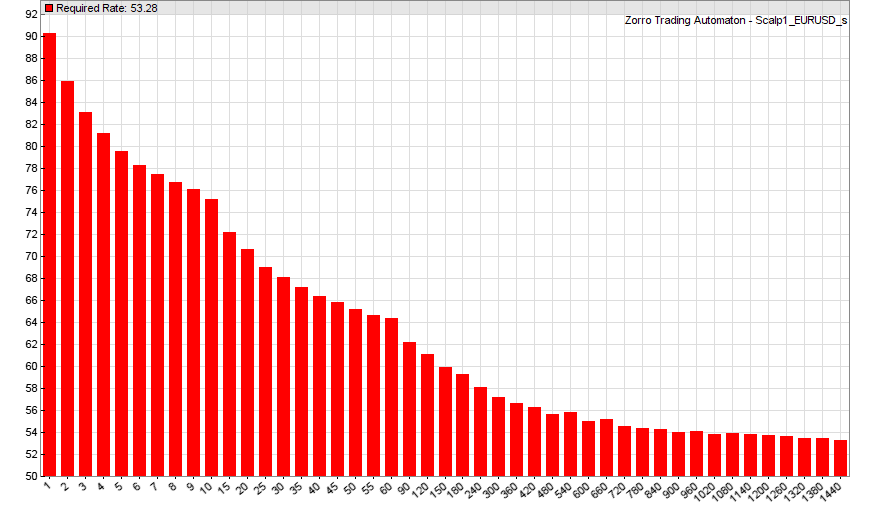
You need about 53% win rate for covering the costs of 1-day trades (rightmost bar), but 90% win rate for 1-minute trades! Or alternatively, a 9:1 reward to risk ratio at 50% win rate. This exceeds the best performances of real trading systems by a large amount, and seems to confirm convincingly the first reason why you better take tales by scalping heroes on trader forums with a grain of salt.
But what about reason number two – that short time frames are plagued with ‘noise’ and ‘randomness’? Or is it maybe the other way around and some effect makes short time frames even more predictable? That’s a little harder to test.
Measuring randomness
‘Noise’ is often identified with the high-frequency components of a signal. Naturally, short time frames produce more high-frequency components than long time frames. They could be detected with a highpass filter, or eliminated with a lowpass filter. Only problem: Price curve noise is not always related to high frequencies. Noise is just the part of the curve that does not carry information about the trading signal. For cycle trading, high frequencies are the signal and low-frequency trend is the noise. So the jaggies and ripples of a short time frame price curve might be just the very inefficiencies that you want to exploit. It depends on the strategy what noise is; there is no ‘general price noise’.
Thus we need a better criteria for determining the tradeability of a price curve. That criteria is randomness. You can not trade a random market, but you can potentially trade anything that deviates from randomness. Randomness can be measured through the information content of the price curve. A good measure of information content is the Shannon Entropy. It is defined this way:
![]()
This formula basically measures disorder. A very ordered, predictable signal has low entropy. A random, unpredictable signal has high entropy. In the formula, P(si) is the relative frequency of a certain pattern si in the signal S. The entropy is at maximum when all patterns are evenly distributed and all P(si) have about the same value. If some patterns appear more frequently than other patterns, the entropy goes down. The signal is then less random and more predictable. The Shannon Entropy is measured in bit.
The problem: Zorro has tons of indicators, even the Shannon Gain, but not the Shannon Entropy! So I have no choice but to write a new indicator, which fortunately is my job anyway. This is the source code of the Shannon Entropy of a char string:
var ShannonEntropy(char *S,int Length)
{
static var Hist[256];
memset(Hist,0,256*sizeof(var));
var Step = 1./Length;
int i;
for(i=0; i<Length; i++)
Hist[S[i]] += Step;
var H = 0;
for(i=0;i<256;i++) {
if(Hist[i] > 0.)
H -= Hist[i]*log2(Hist[i]);
}
return H;
}
A char has 8 bit, so 28 = 256 different chars can appear in a string. The frequency of each char is counted and stored in the Hist array. So this array contains the P(si) of the above entropy formula. They are multiplied with their binary logarithm and summed up; the result is H(S), the Shannon Entropy.
In the above code, a char is a pattern of the signal. So we need to convert our price curve into char patterns. This is done by a second ShannonEntropy function that calls the first one:
var ShannonEntropy(var *Data,int Length,int PatternSize)
{
static char S[1024]; // hack!
int i,j;
int Size = min(Length-PatternSize-1,1024);
for(i=0; i<Size; i++) {
int C = 0;
for(j=0; j<PatternSize; j++) {
if(Data[i+j] > Data[i+j+1])
C += 1<<j;
}
S[i] = C;
}
return ShannonEntropy(S,Size);
}
PatternSize determines the partitioning of the price curve. A pattern is defined by a number of price changes. Each price is either higher than the previous price, or it is not; this is a binary information and constitutes one bit of the pattern. A pattern can consist of up to 8 bits, equivalent to 256 combinations of price changes. The patterns are stored in a char string. Their entropy is then determined by calling the first ShannonEntropy function with that string (both functions have the same name, but the compiler can distinguish them from their different parameters). Patterns are generated from any price and the subsequent PatternSize prices; then the procedure is repeated with the next price. So the patterns overlap.
An unexpected result
Now we only need to produce a histogram of the Shannon Entropy, similar to the win rate in our first script:
function run()
{
BarPeriod = 1;
LookBack = 1440*300;
StartWeek = 10000;
int Duration = 1, i = 0;
while(Duration <= 1440)
{
TimeFrame = frameSync(Duration);
var *Prices = series(price(),300);
if(!is(LOOKBACK) && 0 == (Bar%101)) {
var H = ShannonEntropy(Prices,300,3);
plotBar("Randomness",i++,Duration,H,AVG+BARS,BLUE);
}
if(Duration < 10) Duration += 1;
else if(Duration < 60) Duration += 5;
else if(Duration < 240) Duration += 30;
else if(Duration < 720) Duration += 120;
else Duration += 720;
}
}
The entropy is calculated for all time frames at every 101th bar, determined with the modulo function. (Why 101? In such cases I’m using odd numbers for preventing synchronization effects). I cannot use here the hack with skipping the next 100 bars as in the previous script, as skipping bars would prevent proper shifting of the price series. That’s why this script must really grind through any minute of 3 years, and needs several minutes to complete.
Two code lines should be explained because they are critical for measuring the entropy of daily candles using less-than-a-day bar periods:
StartWeek = 10000;
This starts the week at Monday midnight (1 = Monday, 00 00 = midnight) instead of Sunday 11 pm. This line was missing at first and I wondered why the entropy of daily candles was higher than I expected. Reason: The single Sunday hour at 11 pm counted as a full day and noticeably increased the randomness of daily candles.
TimeFrame = frameSync(Duration);
This synchronizes the time frame to full hours respectively days. If this is missing, the Shannon Entropy of daily candles gets again a too high value since the candles are not in sync with a day anymore. A day has often less than 1440 one-minute bars due to weekends and irregularities in the historical data.
The Shannon Entropy is calculated with a pattern size of 3 price changes, resulting in 8 different patterns. 3 bit is the maximum entropy for 8 patterns. As price changes are not completely random, I expected an entropy value slightly smaller than 3, steadily increasing when time frames are decreasing. However I got this interesting histogram (EUR/USD, 2013-2015, FXCM price data):

The entropy is almost, but not quite 3 bit. This confirms that price patterns are not absolutely random. We can see that the 1440 minutes time frame has the lowest Shannon Entropy at about 2.9 bit. This was expected, as the daily cycle has a strong effect on the price curve, and daily candles are thus more regular than candles of other time frames. For this reason price action or price pattern algorithms often use daily candles. The entropy increases with decreasing time frames, but only down to time frames of about ten minutes. Even lower time frames are actually less random!
This is an unexpected result. The lower the time frame, the less price quotes does it contain, so the impact of chance should be in fact higher. But the opposite is the case. I could produce similar results with other patterns of 4 and 5 bit, and also with other assets. For making sure I continued the experiment with a different, tick-based price history and even shorter time frames of 2, 5, 10, 15, 30, 45, and 60 seconds (Zorro’s “useless” micro time frames now came in handy, after all):
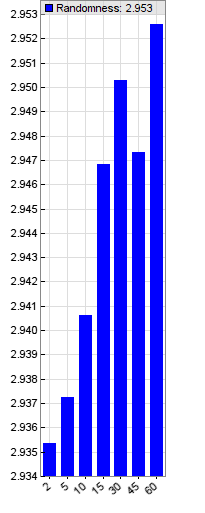
The x axis is now in second units instead of minutes. We see that price randomness continues to drop with the time frame.
There are several possible explanations. Price granularity is higher at low time frames due to the smaller number of ticks. High-volume trades are often split into many small parts (‘iceberg trades‘) and may cause a sequence of similar price quotes in short intervals. All this reduces the price entropy of short time frames. But it does not necessarily increase trade opportunities: A series of identical quotes has zero entropy and is 100% predictable, but can not be traded. Of course, iceberg trades are still an interesting inefficiency that could theoretically be exploited – if it weren’t for the high trading costs. So that’s something to look further into only when you have direct market access and no broker fees.
I have again uploaded the scripts to the 2015 scripts collection. You’ll need Zorro 1.36 or above for reproducing the results. Zorro S and tick based data are needed for the second time frames.
Conclusions
- Scalping is not completely nuts. Very low time frames expose some regularity.
- Whatever the reason, this regularity can not be exploited by retail traders due to the high costs of short term trades.
- On time frames above 60 minutes prices become less random and more regular. This recommends long time frames for algo trading.
- The most regular price patterns appear with 1-day bars. They also cause the least trading costs.
Papers
Shannon Entropy: Lecture
Interesting article – congratulations!
Two details, seemingly contradictory to each other, irritate me:
a) in your histogram ‘Entropy vs. time frame (minutes)’ the value shown for 1 minute is about 2.938.
b) in your histogram ‘Entropy vs. time frame (seconds)’ the value shown for 60 seconds is about 2.952.
I would expect both values to be the same.
Did you change conditions between those runs?
J.M.
Yes, they are based on different history files, the first on a file with M1 bars and the other one on a tick based file.
Ok, but this would mean that those timeframes between 2 and 60 seconds aggregated from tick data seem to have a higher randomness as compared to native M1 data. So I would assume that either the tick data is faulty, or the M1 data, or there’s a bug in the tick data plugin used.
Recently I coded several MT4 scripts to check price data for quality, and the results were horrendous. So my guess would be to look at the price data when trying to find a reason for this mismatch. I think there’s a mismatch, but this does not diminish the basic impact of your analysis: even when trading higher intraday timeframes, always perform a part of your analysis on very short timeframes.
Thank you for the article.
I work with various entropy-related metrics in my ML tasks. Could you please inform what the number of cases you have used per timeframe? I.e., 600 000 for minutes, 100 000 for 60 minutes, etc.? I think something could be improved in your approach.
Alex
When I add a counter to the script and count the number of cases, I get 10000 cases per time frame for the minutes and 16000 cases for the seconds. Minutes were tested from the last 5 years and seconds from January and February 2015.
First of all, each time we compare any results we should have the right understanding of the diff scale between them, eg. does the value 2.95 really differs (in the practice ) with, say, 2.93 or just both of them are equally “high” to us as, say, 3.0 is. In other words, we first have to grade the values: 2.9-3.0 is very high, 2.6-2.9 is just high, 1.8-2.6 is medium and so on, and in our setting both the values 2.93 and 2.95 thus are just “very high” and their diff actually plays no role for us.
Secondly, lets go back and recover what actually we assessed: price patterns which are just are sign series of the price steps. Is this a really good candidate for a “price pattern”? In this setting two situations [+10, -5, +20] and [+1, -1, +1] produce the same “patterns” [+1, -1, +1]. Is that really what we wanted to count? I would suggest, again, to split both X and Y coordinates into a number of “grades”, say, from -5 to 5 (or even -3 to 3 is enough to start) and depict the price pattern as a pixel-picture assigning a number to it. Then do the same – find out if there’s a dominating pattern or some patterns are more likely to appear than others.
Finally, third. As the author stated in the end, not only should we estimate the probability of patterns itself but we also need to be able to “monetize” them somehow. So each pattern, maybe, is to be assigned with a “profitability” weight saying how potentially valuable this pattern is in terms of our trading (even the “perfect trading” – when we can perfectly predict such a pattern). There are no much changes to be made in the formula to support “profitability” factor – just a factor in the probability weight.
Good points. Splitting the price differences into grades would most likely produce a more accurate result since we then have more data. The Shannon Entropy can be monetized in some strategies by using it as a filter, i.e. suspending trades when the entropy is high and thus the market governed by randomness.
It’s an old post but something from our own experience (I’ll try to keep it short)…
We had a very successful trading system consisting of few mean reversion strategies that some people would consider HF. The number of trades was in thousands per week on several currency pairs. The trade lengths varied from few minutes to many hours. The system worked around half a year and we made astonishing 1500% during that period. Well, with very high compound risk and some margin calls but still…:)
What you need:
– $200k+ – i.e. enough money to be able to negotiate your own terms with the broker. The more the better of course but even less than 200k can be sufficient if you are lucky enough.
– A broker with really tight spreads.
– A broker that allows you to pay fixed monthly commission instead of per round turn.
Pitfalls:
– Majority of the Forex brokers are scammers. Those with very low spreads often achieve that by trading on their own exchange (doing market making) and even if they claim that their customer department and trading department are separate they won’t like it if you start earning serious money.
– Even if they claim they provide you with direct market access it’s often not the case
– Small changes in your account parameters (from the broker side) can cause huge changes in the strategy performance so you should monitor everything very closely on daily basis. Even things you wouldn’t consider otherwise.
Conclusion:
(Something like) HFT is possible even for relatively small traders if they are able to find the right tools. It’s not free money and it comes with its own risks and pitfalls from which I’ve mentioned just few.
Hi pcz,
Thanks for sharing your fx experience.
IB claims to give its member DMA for Forex, they also claim to have separate companies for market making and brokage services. Are you targeting them in your comment or just a coicidence? I consider them for my hf-like fc strategy, thats why the question.
Thanks,
I don’t understand why you don’t normalize the entropy to 1 doing “/3” since that 3 it’s just your decision as a max, since you convert to an alphabet of 8 bit. If you use a bigger alphabet of 1000 you get a lower max of 9.96, and if you use a binary one you get 1 as max. In short, since here you just do a comparison between same type of data I don’t understand the meaning of that 3.
The meaning of the 3 is 3 bits, which is simply the entropy value. You can normalize it when you want to compare entropies of different alphabets. Since this is not the case here, I don’t see much of a point in normalizing.
Hi jcl,
Interesting post. I would tackle the problem from another perspective. Since the drift of a stochastic process scales linearly with time while volatility scales with the square root, the higher the frequency the lower the signal/noise. At very high frequency < a few seconds, you can get good result from the order book/flow which is highly predictive. But that is beyond the scope of most trader because of level 2 quote access (altough some fx brokers propose access to it) and of the latency (you will be beaten by HFT traders and be relegated at end of the queue of the book causing at best small losses). Moreover, trading is costly. So, is it hopeless? No! but one has to focus on developping strategy on volatility at short time scale and on issuing limit orders strategically (except in some situations) in order to limit the cost of the spread (of course you have to make a model which is not too latency sensitive). To sum up, Scalping is a pure volatility game…
(I think J. Kinlay wrote a good article long time ago on the mathematics of scalping which explains something similar)
Best,
Lau K
Win rate alone is worthless and very missleading information until you view it together with other important metrics as average trade reward/risk ratio.
Your assumptions on the costs of active day trading seem too pessimistic. I feel you get a more realistic view if you calculate on the pip size of entry and exit stops.
Clearly, active traders have to seek out brokers offering good commissions and tight spreads. And they are restricted to trading the cheaper pairs – but because there are more signals per day this is not an onerous restriction.
At our broker, spread on the Euro is around 0.2 and round-turn commission after volume rebate is 30 units per mio.
Consider a momentum-entry Euro system where the TP is 5 pips and the SL is 2 pips. With such a tight stop, exits are handled client-side to prevent being spiked out by the spread and news trading is avoided.
For a $1 mio winning trade on the Euro:
– The gross pip win is 5 pips – 0.2 pips slippage = 4.8 pips.
– The gross dollar win is a pip value of $100 * 4.8 pips = $480.
– The net dollar win is $480 – $30 commission = $450.
Total costs are $50, a manageable 10% of the gross dollar win. In a winning system, these higher costs are compensated by a much higher capital turn compared to swing or position trading.
– The gross pip loss is 2 pips + 0.2 pips slippage = 2.2 pips.
– The gross dollar loss is $100 * 2.2 pips = $220.
– The net dollar loss is $220 + $30 commission = $250.
The risk/reward ratio after costs is 450/250 = 1.8.
So after costs the breakeven win percentage of this real-life active system is an achievable 36%.
A system that generated a few trades per day with a 50% win rate would be very profitable with reasonable variance. With a win rate over 55% it becomes pretty bombproof. With a good broker negative slippage on entry will reduce profits but still leave them healthy.
These are tough targets but not impossible – I’ve seen systems that achieve this. Active trading can be very rewarding.
I really enjoy your articles. And it’s very humbling (that you can write simple(!) code to demonstrate).
Some of the papers rank with peer reviewed papers.
Needless to say I have benefited a lot from your papers and thanks!
Interesting results. Does this mean that theoretically one minute bars are more predictable than else above it, not including 12 and 24 hrs bars?
Just wanna remark on few general things, The website design is perfect, the written content
is real fantastic :D.
You are a genius! I’m a fan! This is the first article that I’ve read on your blog and I’ll be reading more now. Thank you for such great content.
This is an excellent article. In thecalculation of the size:
int Size = min(Length-PatternSize-1,1024);
I think that it should be:
int Size = min(Length-PatternSize+1,1024)”;
This would give the number of complete patterns within the widow defined by the Length or maybe the definition of size is different?
Thanks for the very helpful article.
Thanks for the comment. Size is Length-PatternSize-1 because otherwise Data[i+j+1] in the loop would overrun the array size.